Solr Can You Upload an Xml Not in the Format
During an upgrade project to Sitecore 9, I got some insights worth sharing. Some findings in this post applies to multiple Sitecore versions and some are specific to Sitecore 9. I've been using SolrCloud 6.6, merely some of it applies to other versions as well. It be came a long, yet very abbreviated, post roofing many areas.
In this post:
- Solr Managed schemas in Sitecore 9
- Melody and extend Solr managed schema to fit your needs
- How to fix Sitecore config for correct Solr indexing and stemming
- How to make switching index piece of work with Solr Cloud
- How to reduce index sizes and gain speed using opt-in
- How to make opt-in work with Sitecore (problems workaround)
- Why
(myfield == Guid.Empty)won't give y'all the event you're expecting
Working with managed schemas
From Sitecore 9, the "Generate the Solr Schema.xml file" command in the Control Panel is gone. Instead there'due south a new "Populate Solr Managed Schema" control. It'll use the REST interface of Solr to update the schema file. Solr tin can share drove configurations. This essentially means that you tin can take multiple collections (formerly known as cores) sharing the same configuration and this is commonly the example. Here'south a get-go finding: It can disharmonize with the Populate Solr Managed Schema command, every bit it'll listing all you indexes and permit you update them all at once. This may event in a race condition, as Sitecore will send multiple commands to update the schema, for multiple indexes, that are sharing the aforementioned schema. To work around this, you should instead check only ane of the indexes and uncheck all the others and click update. Solr volition make certain all the others are the same anyhow. If you lot don't use shared Solr config similar ZooKeeper, you manifestly need to run this for all indexes, and in that case y'all can run them all at once.
Generate Solr Schema.xml in the Control Panel upwardly to Sitecore 8.2
Populate Solr Managed Schema in the Control Panel of Sitecore nine
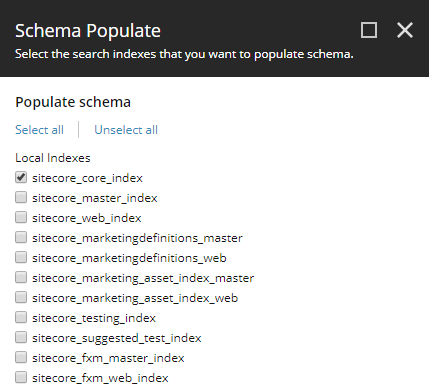
When using shared configuration in Solr, yous should populate the schema for only one alphabetize. Otherwise they may collide.
So, what will Sitecore do with the Solr managed schema when this procedure is execute? It'll add and update the required fields to the schema to make certain Sitecore items can be indexed properly. You'll probably find that you lot want to make boosted changes to schema. Previously we could merely change the schema.xml file to whatever nosotros want. You can still practice this the old mode by setting the <schemaFactory> class to ClassicIndexSchemaFactory in the solrconfig.xml file in your Solr instances and manage your schema.xml manually. However, once yous get the hang of the new style of working with managed schemas, y'all'll probably detect information technology improve. Particularly when working with multiple environments and Solr clusters. Yous'll find it much easier to simply permit Sitecore update everything from the Command Panel, instead of playing around with schema.xml files and ensure they are up to engagement, distributed and loaded properly into all Solr instances.
So how do we tune the managed schema to what we want? Well, y'all could merely manually call the Solr API, only information technology would make more sense to take the application specific configuration together with our Sitecore application code. That'll make a solution less fragmented and easier to go along all environments in sync. Sitecore does this in the <contentSearch.PopulateSolrSchema> pipeline. You can either supersede the existing Sitecore.ContentSearch.SolrProvider.Pipelines.PopulateSolrSchema.PopulateFields processor, given that you provide the necessary functionality, or add your own processor. I constitute it easier to supercede the existing one equally I found a couple of errors in the built in one that I needed to address anyway. Some of the errors are covered in this post, and so I'll describe the supplant scenario here.
You lot can patch the default processor like this:
CustomPopulateSolrSchema.config
<?xml version="one.0" encoding="utf-viii" ?> <configuration xmlns:patch="http://www.sitecore.internet/xmlconfig/" xmlns:search="http://www.sitecore.net/xmlconfig/search/"> <sitecore search:require="Solr"> <pipelines> <contentSearch.PopulateSolrSchema> <processor type="Your.Namespace.PopulateSolrSchemaFields, Your.Associates" patch:instead="processor[@type='Sitecore.ContentSearch.SolrProvider.Pipelines.PopulateSolrSchema.PopulateFields, Sitecore.ContentSearch.SolrProvider']"/> </contentSearch.PopulateSolrSchema> </pipelines> </sitecore> </configuration>
Then you lot'll need to implement the new PopulateSolrSchemaFields class and make an implementation of the ISchemaPopulateHelper interface:
PopulateSolrSchemaFields.cs
namespace Your.Namespace { public form PopulateSolrSchemaFields : Sitecore.ContentSearch.SolrProvider.Pipelines.PopulateSolrSchema.PopulateFields { protected override Sitecore.ContentSearch.SolrProvider.Pipelines.PopulateSolrSchema.ISchemaPopulateHelper GetHelper(SolrNet.Schema.SolrSchema schema) { Assert.ArgumentNotNull(schema, "schema"); render new YourSchemaPopulateHelper(schema); } } public class YourSchemaPopulateHelper : Sitecore.ContentSearch.SolrProvider.Pipelines.PopulateSolrSchema.ISchemaPopulateHelper { private readonly SolrSchema _solrSchema; public YourSchemaPopulateHelper(SolrSchema solrSchema) { Affirm.ArgumentNotNull(solrSchema, "solrSchema"); _solrSchema = solrSchema; } // Implementation goes hither. // Look at and re-create stub code from Sitecore.ContentSearch.SolrProvider.Pipelines.PopulateSolrSchema } } You can reverberate the default implementation Sitecore in Sitecore.ContentSearch.SolrProvider.dll to go an thought of how it works. You'll probably find that the reflected code for GetAddFields() and GetReplaceTextGeneralFieldType() isn't very readable. I refactored this slightly then it became much more readable and managable without changing the logic. Perhaps the original code is readable besides, simply was but messed upwards by the compiler.
Looking at bit deeper into GetAddFields(), I constitute a couple of errors in Sitecores implementation, that is now also comfirmed bugs as by Sitecore. There may be differences between versions and releases of Sitecore, merely I've found the following mapping errors in many viii.x and in all three 9.x releases. And then check these in your configuration:
-
"*_t_en"is incorrectly mapped to"text_general". This should be mapped to"text_en" -
"*_t_cz"is incorrectly mapped to"text_cz". This is initially a problems in Solr referring to Czech. The linguistic communication code for Czech is"cs". So the correct mapping should exist"*_t_cs"to"text_cz", given that you exit the name of the default Solr text stemming configuration for Czech equally is. -
"*_t_no"is mapped to"text_no". "Norwegian" is typically referred to as "Nynorsk" (nn) or "Bokmål" (nb). To brand this work amend, two additional mappings are needed here. Unless you accept specific/custom stemming rules in Solr, you tin can map both"*_t_nn"and"*_t_nb"to"text_no". - An array of
DateTimeis mapped as"{0}_dtm"inSitecore, merely there is no mapping provided for.ContentSearch .Solr .DefaultIndexConfiguration.config "*_dtm", so a multi-value date field needs to be added.
You'll as well discover that the format for updating managed schemas is different from the schema itself. The form generates xml snippets that are sent equally update commands to Solr. A very annoying thing is that wrong update commands are just silently accepted. You'll get a "success"-message in Sitecore regardless if your update snippets are correct and stored in Solr or non. And then make sure you lot read the managed schema file in the Solr UI to verify that the changes have really been stored.
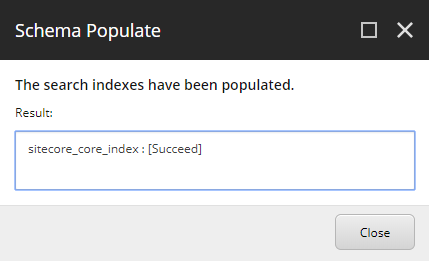
Sitecore may testify a success message even when the managed schema update are not applied in Solr.
A proficient case of the differences between the schema.xml format and the xml structure for updating it, can exist constitute in the GetReplaceTextGeneralFieldType() method. This is also a method worth replacing. Looking closer to its content, it configures text_general to use the default stop words and synonyms filter. Those contains English text in a default setup. This doesn't really make much sense. I believe text_general should be used for languages where there is no stemming back up in Solr. So I suggest you lot remove the stopwords and potentially the synonyms filter.
Look into the managed schema stored in your Solr instance/cluster to ensure your config changes has been applied properly.
You lot may as well find solr.WordDelimiterGraphFilterFactory very useful for stemming things like production names, trade marks, phone numbers, SKU numbers etc. I believe an equivalent filter was configured every bit default in Solr 5.3, but in 6.6 it's not. I found myself working through all the Solr analyzers for all the language definitions to accept good search results. Time consuming, just well worth it.
Here'due south a sample of Solr schema configuration for a Swedish stemmed text field type, leveraging from the WordDelimiterGraphFilterFactory:
<fieldType name="text_sv" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter course="solr.StopFilterFactory" format="snowball" words="lang/stopwords_sv.txt" ignoreCase="true"/> <filter course="solr.WordDelimiterGraphFilterFactory" catenateNumbers="one" generateNumberParts="1" splitOnCaseChange="1" generateWordParts="i" splitOnNumerics="1" catenateAll="0" catenateWords="one"/> <filter form="solr.LowerCaseFilterFactory"/> <filter course="solr.SnowballPorterFilterFactory" language="Swedish"/> </analyzer> </fieldType>
To achieve the configuration higher up, by letting Sitecore update the managed schema, you actually need to produce the XML snippet below in an implementation of ISchemaPopulateHelper interface that Sitecore sends to the Solr API.
<replace-field-type> <name>text_sv</proper noun> <grade>solr.TextField</course> <positionIncrementGap>100</positionIncrementGap> <analyzer> <tokenizer> <course>solr.StandardTokenizerFactory</class> </tokenizer> <filters> <class>solr.StopFilterFactory</course> <ignoreCase>truthful</ignoreCase> <words>lang/stopwords_sv.txt</words> <format>snowball</format> </filters> <filters> <class>solr.WordDelimiterGraphFilterFactory</class> <catenateNumbers>1</catenateNumbers> <generateNumberParts>1</generateNumberParts> <splitOnCaseChange>one</splitOnCaseChange> <generateWordParts>1</generateWordParts> <catenateAll>0</catenateAll> <catenateWords>ane</catenateWords> <splitOnNumerics>1</splitOnNumerics> </filters> <filters> <grade>solr.LowerCaseFilterFactory</form> </filters> <filters> <class>solr.SnowballPorterFilterFactory</class> <language>Swedish</language> </filters> </analyzer> </replace-field-blazon>
As I mentioned above, the compiled and reflected lawmaking of this isn't very readable, so I created a small fluent pattern to generate this configuration. I'k happy to share that code, but I assume Sitecore will have a preferred way of working with this in a near time to come release. @Sitecore: Please reach out to me if you're interested in incorporating my solution into the product.
SolrCloud
Solr includes the ability to prepare up a cluster of Solr servers that combines fault tolerance and high availability. It's at present called SolrCloud, and has the capabilities to provide distributed indexing and search, with cardinal configuration, automatic load balancing and fail-over. SolrCloud is not a cloud service. It's simply a version of Solr. Yous can run the aforementioned SolrCloud application and index index configuration on a single case on your local dev car, besides as on your large scale, sharded and clustered, product instances. Worth noticing is that Solr "cores" are called "collections" in SolrCloud. A "core" in SolrCloud is merely a shard or replica of a collection.
To make Sitecore work well with Solr, you should use switching indexes. Otherwise your indexes will be blank during rebuilds! To make this work with SolrCloud, you'll need to use the Sitecore alphabetize type. The idea is that you accept two Solr collections for every index together with two aliases. The primary alias points to one of the indexes and a rebuild alias points to the other alphabetize. So after alphabetize rebuild, Sitecore will bandy the 2 aliases. This means a fully functional index is e'er available even when rebuilding the index.
The constructor of SwitchOnRebuildSolrCloudSearchIndex uses a few more arguments to make this piece of work. When this is defined in the config files, the constructor arguments are only listed as a <param> list. This makes it a bit tricky to patch properly, since information technology'due south somewhat tricky to ensure the society of the <param> list from Sitecore patch files. What'southward worse is that if you get those arguments wrong, Sitecore just won't start. You lot can't even use the /sitecore/admin/ShowConfig.aspx page. Doh!
Sitecore 9 besides introduced a new problems regarding switching indexes. Currently y'all must fix the ContentSearch setting to true. Otherwise, Sitecore won't update the Solr alphabetize aliases properly afterward a rebuild. But ensure not to exercise this on your Content Delivery servers. Otherwise you'll stop up with multiple servers switching the aliases ending up in undefined states.
Another mutual issue with Solr is that commits of big updates takes longer time than the default timeout, causing exceptions on the Sitecore client side. Nosotros can but increment the timeout past changing the ContentSearch setting. Note that the timeout is specified in milliseconds, then 600000 will requite a ten minute timeout. The terminal commit after a total alphabetize rebuild can easily take a few minutes.
Resently I became enlightened of another setting, ContentSearch.SearchMaxResults, that you really should prepare. This setting tells Sitecore how many rows should be returned from Solr, unless you specify a .Take(due north) Linq expression in your queries. By default, the value of this field is empty, causing Sitecore to ask for int.Max, i.due east. 231-1 =
If you lot're using SolrCloud 6.6 in a clustered and sharded environment you lot might also run into the following strange behavior, unless you reduce SearchMaxResults. It turns out that Solr is a fleck buggy when rows gets close to int.Max. When a telephone call to Solr has the rows parameter set to int.Max (231-1), I got a strange "NegativeArraySizeException" from Solr. If I send int.Max+1 (231), I get a more sensible NumberFormat exception from Solr and that'south completely fine. If I transport int.Max-1 (two31-2) I become an IllegalArgumentException, with the bulletin "maxSize must be <= 2147483630" (231-17). If I ship that specified max number, I get a coffee heap OutOfMemoryError… Running SolrCloud on a unmarried server instance, naught of this is reproducible. Very foreign… and y'all may non get much valuable information about this on the Sitecore side… So just ready ContentSearch.SearchMaxResults and y'all're skilful to go.
If y'all, like me, prefer reading lawmaking, the above can be summarized in a config template similar this:
<?xml version="1.0" encoding="utf-8" ?> <configuration xmlns:patch="http://www.sitecore.internet/xmlconfig/" xmlns:fix="http://world wide web.sitecore.net/xmlconfig/set/" xmlns:role="http://world wide web.sitecore.net/xmlconfig/role/" xmlns:search="http://www.sitecore.net/xmlconfig/search/"> <sitecore search:crave="Solr"> <sc.variable name="solrIndexPrefix" value="my_sc9_prefix" /> <settings> <setting name="ContentSearch.Solr.ConnectionTimeout" set:value="600000" /> <setting proper name="ContentSearch.Solr.EnforceAliasCreation" prepare:value="true" office:require="ContentManagement or Standalone" /> <setting name="ContentSearch.SearchMaxResults" fix:value="1000" /> </settings> <contentSearch> <configuration> <indexes> <alphabetize id="sitecore_master_index" blazon="Sitecore.ContentSearch.SolrProvider.SwitchOnRebuildSolrCloudSearchIndex, Sitecore.ContentSearch.SolrProvider" solrPrefix="$(solrIndexPrefix)" office:require="ContentManagement or Standalone"> <param desc="name">$(id)</param> <param desc="mainalias">$(solrPrefix)_$(id)</param> <param desc="rebuildalias">$(solrPrefix)_$(id)_Rebuild</param> <param desc="collection">$(solrPrefix)_$(id)_1</param> <param desc="rebuildcollection">$(solrPrefix)_$(id)_2</param> <param ref="contentSearch/solrOperationsFactory" desc="solrOperationsFactory" /> <param ref="contentSearch/indexConfigurations/databasePropertyStore" desc="propertyStore" param1="$(id)" /> ... ... </index> </indexes> </configuration> </contentSearch> </sitecore> </configuration>
Solr Opt-in
By default, Sitecore indexes all fields. This ways that Sitecore will send the content of all fields to Solr for indexing, look the ones that you explicitly exclude from indexing (Opt-out). This may be ok for modest solutions, but for large solutions, this volition crusade indexes to become very large and indexing to be CPU heavy and time consuming.
If y'all don't brand queries on a field or use the stored result, you lot don't need it in the index. So why index it and then? It's just a waste product of resources. Note that free text search isn't afflicted by this, every bit this is typically fabricated on computed fields, such as _content or a more than suitable computed field you make yourself.
The <indexAllFields> element controls this in the <indexConfiguration> section. When setting information technology to false, Sitecore volition only index the fields you explicitly include for indexing (Opt-in). I'd recommend you fix this to false when starting new projects, since changing this to false later on could potentially require code refactoring and a lot of testing.
Sitecore has confirmed a problems in AbstractDocumentBuilder<T> when using opt-in. There is an if-statement in the AddItemFields() method, that merely loads all field values when using opt-out. So when using opt-in, fields with nil values won't be properly indexed. This ways that values coming from standard values, clones or language fallback won't be indexed. This seems to apply to almost versions of Sitecore, simply luckily it's a very unproblematic patch:
SolrDocumentBuilder.cs
public class SolrDocumentBuilder : Sitecore.ContentSearch.SolrProvider.SolrDocumentBuilder { public SolrDocumentBuilder(IIndexable indexable, IProviderUpdateContext context) : base of operations(indexable, context) { } protected override void AddItemFields() { Indexable.LoadAllFields(); base.AddItemFields(); } } SolrDocumentBuilder.patch.config
<configuration xmlns:patch="http://www.sitecore.cyberspace/xmlconfig/" xmlns:fix="http://www.sitecore.net/xmlconfig/prepare/" xmlns:office="http://www.sitecore.cyberspace/xmlconfig/role/" xmlns:search="http://www.sitecore.net/xmlconfig/search/"> <sitecore role:crave="Standalone OR ContentManagement OR ContentDelivery OR Processing OR Reporting" search:require="Solr"> <contentSearch> <indexConfigurations> <defaultSolrIndexConfiguration blazon="Sitecore.ContentSearch.SolrProvider.SolrIndexConfiguration, Sitecore.ContentSearch.SolrProvider"> <documentBuilderType>Your.Namespace.SolrDocumentBuilder, Your.Associates</documentBuilderType> </defaultSolrIndexConfiguration> </indexConfigurations> </contentSearch> </sitecore> </configuration>
Going for an opt-out solution does give y'all some more than work, so is there a existent gain of the opt-out arroyo? I recently converted 1 of our existing solutions from opt-out to opt-in principle. The size of the Solr indexes was reduced from near 70GB to 3.5GB. Index time was reduced from 4 hours to thirty minutes on a 16 core/64GB RAM server. I remember those figures speaks for themselves and your queries will exist faster too.
Tricky ContentSearch Linq to Solr bug
Recently I noticed a Sitecore ContentSearch query that didn't return the result I was expecting. It took a while to really become a hold of what was really going on. I can't fully disembalm what kind of queries I'1000 performing in that project, and so I've translated this into a more than generic scenario that I also promise makes information technology easier to sympathize the effect.
Let'southward say you lot accept a site with a lot of pages and you want to generate a sitemap.xml page. You can do this by querying all your indexable pages that has a layout and so on and merely make an xml output of it. Now, let'south say you have some deprecated pages, indistinguishable content or whatever that you don't desire to exist indexed. A way of solving that could be to have a approved link to an alternative folio containing the equivalent content. That can just be stored in a DropLink Sitecore field and we return it as a <canonical /> html tag.
Manifestly we don't want to include those pages having a canonical link pointing to an alternative page in the sitemap xml. And so we simply construct our Sitecore ContentSearch query like this, correct?
var pages = searchContext.GetQueryable<SitemapDocument>() .Filter(f => f.IsLatestVersion && // More filters here apparently to get simply pages with layouts etc... f.CanonicalLink == Guid.Empty) .GetResults() .Select(r => r.Document) ... ... public class SitemapDocument { [IndexField("_latestversion")] public bool IsLatestVersion { become; ready; } [IndexField("canonicallink")] public Guid CanonicalLink { get; set; } ... ... } Well, it turns out that the above doesn't work! Why?
Well, Guid isn't a nullable type, and so Guid.Empty is actually {00000000-0000-0000-0000-000000000000} and is indexed as 00000000000000000000000000000000. I'll abridge this as 000… from now on. And then, when Sitecore indexes a blank Guid field, it'll index it as 000… When searching a field == Guid.Empty, similar in the sample code in a higher place, Sitecore will make a Solr query looking like this:
?q=*.*&fq=(_latestversion:(True) AND canonicallink_s:(000....)...
This means that if an item doesn't have the Canonical link field, it won't be returned.
I've tried all sorts of ways to solve this. I've tried making the property a nullable Guid, making it a cord field and then on. So have Sitecore support and this is at present a confirmed bug (though I'k not sure the root cause was properly provided to production department).
I think that an empty guid should never be stored as 000… in the index. If there is no guid, in that location should be no data in the alphabetize either, i.e. cipher. Likewise, if 000…. is actually stored in a guid field it should also be indexed as null. At query time, I call up a field == Guid.Empty statement should be serialized to -field_s:*. This would make the query behavior consequent and somewhat reduce the alphabetize size as well.
The all-time way I've establish to workaround this for at present, is to exclude (or not include if you're post-obit my recommendations higher up) the canonical field from the index entirely and replace it with a computed field that'll always return the link Guid, or Guid.Empty regardless if the field is empty or non present on the item being indexed. Never return null. That manner the query will always return correct data.
Note that the inverted query works just fine. A query like field != Guid.Empty does give the expected result.
Closing
Okay, this was a very long first postal service of my 6th year equally a Sitecore MVP. Hope you find it valuable and please share your thoughts on this. I'd love to hear your experiences in this area. Have you all ran into these issues as well, or is it only me pushing some boundaries once again?
Btw, take you noticed the Index Manager dialog result message, "Finished in Ten seconds"? The value isn't accurate when edifice multiple indexes. Do you lot see what's wrong? Information technology's a confirmed issues too, but I doubtfulness it'll ever be corrected, and I'thou perfectly fine with that. It's a cosmetic issues well beneath pocket-sized level.
Source: https://mikael.com/2018/01/working-with-content-search-and-solr-in-sitecore-9/
{kind=link}
Post a Comment for "Solr Can You Upload an Xml Not in the Format"